OpManager中的设备模板包含预定义的规则,在发现设备后将根据这些规则对设备进行分类和关联相关的监视器。为新设备类型定义自定义模板或修改现有模板以在同一个模板中容纳另一种设备类型的能力为管理员提供了很大的灵活性。也就是说,作为一名管理员,如果能够充分利用该特性的潜力,您将能够充分利用该特性。例如,有些可能会为设备类型的每个变体定义一个模板,而不是创建一个可以包含所有变体的模板。理想情况下,在启动发现之前定义设备模板有助于进行正确的分类。超过650个设备模板可以开箱即用。如果在被监视的设备上启用了SNMP,并且在OpManager中配置了适当的凭证,那么大多数设备属于正确的类别。根据需要修改现有模板或创建新模板。
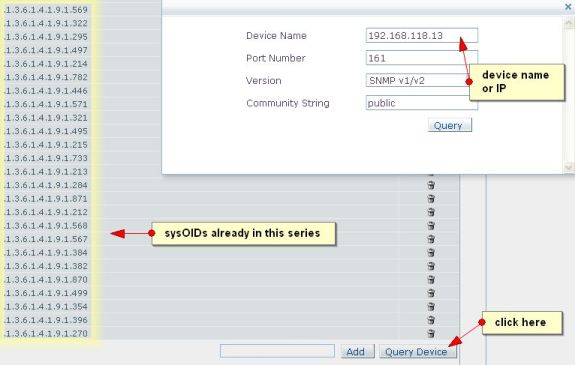
假设您购买了一个新的Cisco 805路由器,您想要使用OpManager监控它。OpManager已经为Cisco 800系列路由器提供了一个设备模板,在模板中更新了这些系列路由器中的一些sysoid。你所需要做的就是编辑这个模板来包含思科805路由器的sysOID(如果它还不存在的话)。
假设您有一组全新的可管理的环境传感器(支持SNMP)。这些设备不能归入任何默认的类别,如服务器、路由器、交换机等,应该归入单独的类别。这个新设备类型的管理参数也不同。定义一个新的类别视图(如传感器)和定义一个新的设备模板的理想情况。您可以在一个模板中使用来自同一供应商的不同型号的传感器,甚至可以在同一个模板中组合来自多个供应商的传感器。
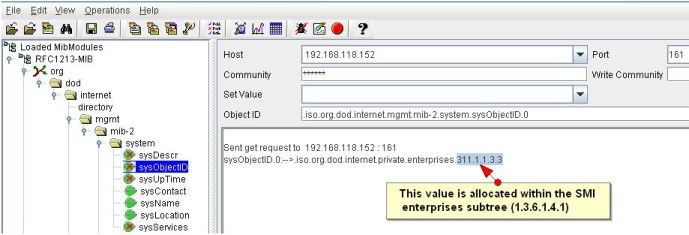
甚至在您继续添加或修改模板以容纳新设备类型之前,请确保该设备已启用SNMP并响应来自OpManager的查询。调用与OpManager绑定的MibBrowser工具来检查响应。让我向您展示如何检查SNMP响应。
1. 从OpManager/bin中,双击执行MibBrowser.bat。
2. 在MibBrowser GUI中,输入设备名称、SNMP端口和read社区字符串(默认为PUBLIC)。
4. 从上面的工具栏中,单击Get SNMP变量图标(从左边开始的第7个图标),以查看右侧文本区域中的响应。
监视基本的CPU、内存和磁盘利用率可以很好地指出问题可能在哪里,但是要真正确定应用程序缓慢的原因,您需要监视的不仅仅是资源利用率。多个系统资源参数甚至单个参数都可能影响应用程序的性能。让我们看看“磁盘I/O”——导致应用程序性能相关问题的关键参数之一。
硬盘是服务器上最慢的组件之一。硬盘驱动器的带宽大约比内存慢300倍,再加上内存延迟非常低——如果你计算一下,内存的运行速度大约比硬盘驱动器快2000倍。查看http://nathanaeljones.com/153/performankiller-disk-io/可以得到一个简洁的解释。
根据您的服务器,有不同的方法来查找磁盘I/O。有关各种服务器上的磁盘I/O命令,请参考http://www.performancewiki.com/diskio-tuning.html。
另一种简单的方法,也是我们推荐的;)是使用OpManager。OpManager可以对Windows服务器的磁盘I/O进行开箱即用的监视(见下面的截图),还可以对基于unix的设备进行一些定制。

Active Directory monitors show N/A
This problem could due to the following reasons:
1)WMI is not configured properly in OpManager (OpManager uses WMI credential to monitor AD servers).
2)Required Monitors are not associated to the device in OpManager.
3)WMI might not be responding to the OpManager WMI request
4)WMI is not working properly on the device itself.
1)WMI is not configured properly in OpManager (OpManager uses WMI credential to monitor AD servers).
Configure WMI for multiple devices at a time:
1.Go to Admin --> Credential Settings
2.Click New
3.Configure the following parameters and click Add to add the credentials:
Credential Type: Windows
Name: Configure a name for the credential and also provide the description.
Configure the Domain NameU ID and the password (Example:- TestDomainTestUser Testpassword) > Click on "Add".
Associate the above credential using Quick Configuration Wizard to multiple devices:
1. From the Admin tab, select Quick Configuration Wizard.
2. Select the option Associate a credential to several devices and click Next.
3. All the available Credentials are listed. Select the Credential (the one you created above ).
4. Select the devices to which you want to assign the credential from the left column and move them to the right.
5. Click Finish. The Credential is associated to the selected devices.
Configuring WMI credential using device snap shot page(Single device):
Go to device snap shot page > Click on "Click here to change" option besides Passwords >select "Use the below credential for the device" option >Type in the username (Ex:domainnameuame) and Password > Click on Test credential (make sure its gets passed) and then Ok to save it.
In case OpManager itself is hosted on the AD server, then leave the username and password blank and click OK, as local host does not require the credentials.
2)Required Monitors are not associated to the device in OpManager.
Solution: Adding monitors for AD Monitors:-
Make sure the Category is selected as Domain controller to have the AD monitors associated automatically to the device.
In case if the monitors are absent go to  Active Directory Monitors section of the device snapshot page and add the required AD monitors (Network Monitors ,Database Monitors NTFRS Process Monitors , System Monitors, Performance Counters Monitors and LSASS Process Monitors ).
Active Directory Monitors section of the device snapshot page and add the required AD monitors (Network Monitors ,Database Monitors NTFRS Process Monitors , System Monitors, Performance Counters Monitors and LSASS Process Monitors ).
3)WMI might not be responding to the OpManager WMI request
Solution:Use the wmiadap utility to update the WMI performance classes from the performance libraries. Running wmiadap updates all the performance classes. The /f switch in the below command forces an update of the WMI classes from the performance libraries.
Step 1:
1. Go to the monitored device.
2. Click Start-->Run,
For Windows 2000 winmgmt /resyncperf' command.
For Windows XP and 2003 'wmiadap /f' command.
3. After running this command about 4 times, wait for an hour and check whether AD monitors shows data.
Step: 2
1. Go to the monitored device.
2. Click Start-->Run-->services.msc
3. Restart WMI service
4)WMI is not working properly on the monitored device.
Solution: Still if you do not see the counter values, verify whether OpManager server is able to pull up AD counters information by executing the following queries.If you are able to pull the information for the following queries OpManager should be able to show the information in the dashboard.
If some of the below query gets the output and some of them not then the respective counters information associated with the non working classes will not be shown on the dash board.
1. From OpManager command prompt go to <OpManagerconfapplicationscripts>
2. Execute the following commands and make sure we get the output from the device.
cscript wmiget.vbs devicename domainnameuame password "ROOTCIMV2" "SELECT * from Win32_PerfRawData_PerfNet_Server"
cscript wmiget.vbs devicename domainnameuame password "ROOTCIMV2" "SELECT * from Win32_Processor"
cscript wmiget.vbs devicename domainnameuame password "ROOTCIMV2" "SELECT * from Win32_PerfRawData_PerfOS_System"
cscript wmiget.vbs devicename domainnameuame password "ROOTCIMV2" "SELECT * from Win32_PerfRawData_PerfOS_Memory"
cscript wmiget.vbs devicename domainnameuame password "ROOTCIMV2" "SELECT * from Win32_PerfRawData_NTDS_NTDS"
cscript wmiget.vbs devicename domainnameuame password "ROOTCIMV2" "SELECT * from Win32_PerfRawData_PerfProc_Process"
cscript wmiget.vbs devicename domainnameuame password "ROOTCIMV2" "SELECT * from Win32_OperatingSystem"
cscript wmiget.vbs devicename domainnameuame password "ROOTCIMV2" "SELECT * from Win32_LogicalDisk"
cscript wmiget.vbs devicename domainnameuame password "ROOTCIMV2" "SELECT * from Win32_PerfRawData_PerfOS_Processor"
If you are getting "Invalid class" error message for the above queries then either the corresponding wmi classes are absent or corrupted on the AD server.
Please refer the link below to re-register or rebuild the WMI classes.
http://windowsxp.mvps.org/repairwmi.htm
MSSQL 2000/2005 not working - Shows N/A
This problem could due to the following reasons:
1)WMI is not configured properly in OpManager (OpManager uses WMI credential to monitor MSSQL servers).
2)Required Monitors are not associated to the device in OpManager.
3)WMI might not be responding to the OpManager WMI request
4)WMI is not working properly on the device itself.
1)WMI is not configured properly in OpManager (OpManager uses WMI credential to monitor MSSQL servers).
Solution: Configuring WMI for multiple devices at a time :
1.Go to Admin --> Credential Settings
2.Click New
3.Configure the following parameters and click Add to add the credentials:
- Credential Type: Windows
- Name: Configure a name for the credential and also provide the description.
- Configure the Domain NameU ID and the password (Example:- TestDomainTestUser Testpassword) > Click on "Add".
Associate the above credential using Quick Configuration Wizard to multiple devices:-
1. From the Admin tab, select Quick Configuration Wizard.
2. Select the option Associate a credential to several devices and click Next.
3. All the available Credentials are listed. Select the Credential (the one you created above ).
4. Select the devices to which you want to assign the credential from the left column and move them to the right.
5. Click Finish. The Credential is associated to the selected devices.
Configuring WMI credential using device snap shot page(Single device):
Go to device snap shot page > Click on "Click here to change" option besides Passwords >select "Use the below credential for the device" option >Type in the username (Ex:domainnameuame) and Password > Click on Test credential (make sure its gets passed) and then Ok to save it.
In case OpManager itself is going to be MSSQL server then leave the username and password blank and click OK as we do not require credential for the local host.
2)Required Monitors are not associated to the device in OpManager.
Solution: Adding monitors for MSSQL Monitors:-
Here are the steps to associate the MSSQL monitors to a device:
1.Go to the snapshot page of a device.
2.Scroll down and select the Monitors tab.
3.Click on Performance Monitors. The monitors are listed on the right.
4.Click the Add Monitor button on the right. A list of monitors is displayed.
5.Click the MSSQL Monitors button on top of this list. The monitors of all the MSSQL parameters are displayed.
6.From this list, select the required MSSQL Monitors and click on Add > List of MSSQL databases will be listed for which you want to associate Monitors
7.Check mark all the required databases and click on OK , Now you will get a dash board for MSSQL and data will be populated after some time.
3) WMI might not be responding to the OpManager WMI request
Solution:Use the wmiadap utility to update the WMI performance classes from the performance libraries. Running wmiadap updates all the performance classes. The /f switch in the below command forces an update of the WMI classes from the performance libraries.
Step 1:
1. Go to the monitored device.
2. Click Start-->Run,
For Windows 2000 winmgmt /resyncperf' command.
For Windows XP and 2003 'wmiadap /f' command.
3. After running this command about 4 times, wait for an hour and check whether MSSQL monitors shows data.
Step: 2
1. Go to the monitored device.
2. Click Start-->Run-->services.msc
3. Restart WMI service
4)WMI in the device is not working properly.
Solution: Still if you do not see the counter values, verify whether OpManager server is able to pull up MSSQL counters information by executing the following queries.If you are able to pull the information for the following queries OpManager should be able to show the information in the dashboard.
If some of the below query gets the output and some of them not then the respective counters information associated with the non working classes will not be shown on the dash board.
1. From OpManager command prompt go to <OpManagerconfapplicationscripts>
2. Execute the following commands and make sure we get the output from the device.
cscript wmiget.vbs <Devicename or IP> <DomainnameUame> <Password> ROOTCIMV2 "select * from Win32_PerfRawData_MSSQLSERVER_SQLServerBufferManager "
Example:OpManagerconfapplicationscripts>cscript wmiget.vbs MSSQLSERVER1 TestUame Password ROOTCIMV2 "select * from Win32_PerfRawData_MSSQLSERVER_SQLServerBufferManager "
cscript wmiget.vbs <Devicename or IP> <DomainnameUame> <Password> ROOTCIMV2 "select * from Win32_PerfRawData_MSSQLSERVER_SQLServerCacheManager "
cscript wmiget.vbs <Devicename or IP> <DomainnameUame> <Password> ROOTCIMV2 "select * from Win32_PerfRawData_MSSQLSERVER_SQLServerPlanCache "
cscript wmiget.vbs <Devicename or IP> <DomainnameUame> <Password> ROOTCIMV2 "select * from Win32_PerfRawData_MSSQLSERVER_SQLServerDatabases"
cscript wmiget.vbs <Devicename or IP> <DomainnameUame> <Password> ROOTCIMV2 "select * from Win32_PerfRawData_MSSQLSERVER_SQLServerGeneralStatistics "
cscript wmiget.vbs <Devicename or IP> <DomainnameUame> <Password> ROOTCIMV2 "select * from Win32_PerfRawData_MSSQLSERVER_SQLServerReplicationAgents "
cscript wmiget.vbs <Devicename or IP> <DomainnameUame> <Password> ROOTCIMV2 "select * from Win32_PerfRawData_MSSQLSERVER_SQLServerLocks"
cscript wmiget.vbs <Devicename or IP> <DomainnameUame> <Password> ROOTCIMV2 "select * from Win32_PerfRawData_MSSQLSERVER_SQLServerMemoryManager"
cscript wmiget.vbs <Devicename or IP> <DomainnameUame> <Password> ROOTCIMV2 "Select * from Win32_PerfRawData_MSSQLSERVER_SQLServerGeneralStatistics"
If you are getting "Invalid class" error message for the above queries then either the corresponding wmi classes are absent or corrupted on the MSSQL server.
Please refer the link below to reregister or rebuild the WMI classes.
http://windowsxp.mvps.org/repairwmi.htm
Enabling SNMPv3 on Windows 2003
In Windows 2003 Server, SNMP service is available which supports onlySNMP version v1 and v2c. If you want to add SNMPv3 support, you need toinstall snmpv3 supported agent. Download the Net-Snmp Agent tosupport the same.
Please follow the below steps to install snmpv3 agent.
1. First Download the Active Perl from the below link
http://downloads.activestate.com/ActivePerl/Windows/5.10/ActivePerl-5.10.0.1002-MSWin32-x86-283697.msi
2. Install the Active perl first. Also you need to install the OpenSSL.
3. Download the exe of NetSnmp Agent from the below link
http://sourceforge.net/project/showfiles.php?group_id=12694&package_id=162885
4. Install the Net-Snmp Agent.
5.After installing the netsnmp agent. Herewith I have attached the conffile, Please rename the snmp.conf.txt as snmp.conf and snmpd.conf.txtas snmpd.conf. Copy the the snmpd.conf and snmp.conf under thedirectory c:utcsnmp
6. Then register the agent by executing registeragent.bat file and run the below command in command line to start the agent.
net start "net-snmp agent"
7. Now the agent is started at port 8001.
Releated Links:
http://www.netadmintools.com/art487.html
Enabling SNMP on ESX Server
To enable SNMP on ESX Server version 3.5:
1. Login as root
2. Edit the snmpd.conf file and add "rocommunity xxxx" where xxxx is your read-only community string). The file is uusually located in /etc/snmpd.
3. While you're editing the snmpd.conf file, also add "dlmod SNMPESX /usr/lib/vmware/snmp/libSNMPESX.so"
4. Restart the SNMP daemon - /etc/init.d/snmpd restart
In some cases, you may also need to edit the firewall settings on the ESX server to allow the SNMP traffic through. To do this:
Login as root and issue the following commands:
2. esxcfg-firewall -e snmpd
3. chkconfig snmpd on
4. service snmpd start
For more information, visit the VM Ware page on how to configure SNMP on the ESX Server.
Installing OpManager as a Linux service
You can run OpManager as a Unix Service.
Follow the steps mentioned below to install OpManager as a service on a linux box.
1. Copy the content given in blue below to a text file and save it to /etc/init.d directory as opmanager.
#!/bin/bash
#
# Startup script for the pmagent
#
# chkconfig: 345 99 02
# description: Run the OpManager 5 program
INITLOG_ARGS=""
prog="opmanager"
progname="AdventNet ManageEngine OpManager"
RETVAL=0
# Edit the following to indicate the 'bin' directory for your installation
MDIR=/usr/local/OpManager/bin
PRG=$MDIR/opmanager
if [ ! -d "$MDIR" ]
then
echo "Invalid directory $MDIR"
exit 1
fi
start()
{
mv -f /var/log/opmanager.log /var/log/opmanager1.log
echo "Starting $progname"
cd $MDIR
nohup sh StartOpManagerServer.sh >/var/log/opmanager.log 2>&1 &
RETVAL=$?
echo
[ $RETVAL = 0 ] && touch /var/lock/subsys/OpManager
}
stop()
{
echo "Stopping $progname"
cd $MDIR
sh ShutDownOpManager.sh admin admin >>/var/log/opmanager.log 2>&1
}
case "$1" in
start)
start
;;
stop)
stop
;;
*)
echo "Usage: $prog {start|stop}"
exit 1
;;
esac
exit $RETVAL
mv /etc/init.d/opmanager.txt /etc/init.d/opmanager
2. Edit the MDIR variable in this file which should point to the bin folder of OpManager Installation directory. Typically, the default installation folder on a Linux box will be /root/ManageEngine/OpManager/bin. Hence the value for MDIR will be
MDIR=/opt/ManageEngine/OpManager/bin
3. Provide executable permissions for this script using
chmod 755 /etc/init.d/opmanager
4. Use chkconfig command to add opmanager as a service
chkconfig --add opmanager
You can start OpManager in the nohup mode so you don't have to worry about the service being terminated when the console is closed. The service will continue to run in the background. Make these changes in the start and stop script files of OpManager:
in start
nohup /opt/ManageEngine/OpManager/bin/StartOpManagerServer.sh
in stop
nohup /opt/ManageEngine/OpManager/bin/ShutDownOpManager.sh
You might encounter errors such as 'command not found'. Its possible that few relevant library files are not available on the system on which you are trying to install OpManager. Install the packages and proceed with OpManager installation. For instance, if you encounter such an issue in Ubuntu, here is what you need to do:
$ apt-get install libnewt0.51
$ ln -s /usr/lib/libnewt.so.0.51 /usr/lib/libnewt.so.0.50
$ wget http://www.tuxx-home.at/projects/chkconfig-for-debian/chkconfig_1.2.24d-1_i386.deb
$ dpkg --force-all -i chkconfig_1.2.24d-1_i386.deb
Source : http://ubuntuforums.org/archive/index.php/t-20583.html
Registering OpManager License
1. In the Client window, click Register link on the menu bar.
2. Browse and select the Registered License file (AdventNetLicense.xml) provided to you and click Register.
3. Verify the licensing details displayed in the page and click Close.
If you are applying the Registered License after expiry of the evaluation license then do the following:
1.Start the server. You will see the message "Trial Period has Expired".
2. Click OK to enter the License details.
3. Browse and select the Registered License file (AdventNetLicense.xml) provided to you and repeat the steps mentioned above.
Extending trial license
You need to procure the extended trial license from Manageengine. This is provided purely on discretion. Send an email request to sales@manageengine.com
What is a .ppm file?
It is an abbreviation for Package for Patch Manager and has nothing to do with Perl. The File with .ppm extension is known to work with the Update Manager tool which is bundled with AdventNet Products. This tool helps to upgrade to the newer version keeping the data intact. In OpManager,you can access this tool using Start -> Programs ->ManageEngine OpManager -> Update Manager. Alternatively, you canalso invoke the tool from /opmanager/bin/UpdateManager.bat/sh.
Prerequisites for monitoring WAN RTT
The OpManager WAN RTT Monitor monitors the latency between two locations using Cisco's IP-SLA, therefore either of the locations should have the Cisco router enabled with IPSLA agent which will act as a source and the target can be any IP in the other location(Need not be a cisco router).
Prerequisites for MSSQL as backend DB
OpManager can create a database and its tables only if the MSSQL account has DBOwner privilege. It connects to MSSQL server using SQL username and password. So have to enable SQL authentication.
For default MSSQL instance,port number will be 1433.
http://msdn.microsoft.com/en-us/library/ms177440.aspx
http://support.microsoft.com/kb/823938
For named instance, DB host should be entered as hostnameinstancename
Prerequisites to view detailed traffic reports from NFA in OpManager
To view the detailed traffic report from Netflow Analyzer, the prerequisites are,
- Netflow Analyzer must be up and running in your network
- The interface whose traffic you would like to monitor must be discovered in both, OpManager and Netflow Analyzer.
- The NetFlow Analyzer settings must be configured properly in OpManager
What to do if the VMware devices are not displayed under the Virtual Devices map?
If the device has been added successfully, but not displayed under the Virtual Devices map, search for that device. Go to its snapshot page and look for the device type. If it is mentioned as ‘unknown’, wrong credentials might have been provided or it is not reachable during discovery. Provide the correct credentials and click on ‘Rediscover Now’ under Actions tab in the snapshot page, to discover it as an ESX host.
Why should I install VMware Tools?
OpManager, with the help of installed VMware Tools, identifies the IP address of the VM and maps it to the host. In case the VMware Tools are not installed, OpManager discovers it using VM's entity name. You can assign the IP address for such VMs in the host snapshot page (screenshot of the same is given below). Click on the 'No IP Address' link corresponding to the VM to assign the IP address for that VM. Similarly, you can click the assigned IP address to choose another one as the primary IP for that particular VM.
What is CIDR?
CIDR, short for Classless Inter-Domain Routing, is a replacement for the older Classful network addressing architecture that was in use since 1981. CIDR was introduced in 1993 to address the issue of IP address shortage.
The CIDR method divides the address space for Internet Protocol Version 4 (IPv4) into five address classes. Each class, coded in the first four bits of the address, defines either a different network size, i.e. number of hosts for unicast addresses (classes A, B, C), or a multicast network (class D). The fifth class (E) address range is reserved for future or experimental purposes. Now, IPv6 is fast replacing IPv4 allowing huge expansion for more users and devices on the internet.
What is a seed device?
A seed device is the core switch in your network. The switch must have SNMP-enabled so that OpManager is able to query the device and draw the links automatically, showing the connectivity of all the devices on your network. As changes happen to the networks frequently, OpManager allows you to configure an interval (in days) to re-draw the map. For instance, if a change happens once in a week, you can configure OpManager to re-draw the map every seven days.
What leads to the error "Interface associated with this link does not exist in OpManager"?
After layer 2 discovery and mapping, whenever a link on the map is clicked, the error "Interface associated with this link does not exist in OpManager", pops up.
The interface link connected between the two network devices may not be added in OpManager. Hence the pop up message. for instance, lets say Router1 is connected to Router2 through interface Ethernet0/0 of Router1. In case the Ethernet0/0 interface is not added in Router1, you will encounter the above error. Once you add the interface in Router1 by rediscovering the interfaces and try to draw the map, you will get the interface traffic details in the pop up message.
Can't draw a network map! Encounter the message: "No switch links found for this device. Please select different seed device." Why?
This error is encountered when configuring a seed file for Layer2 mapping.
In order to get the networks map, the switches should support SNMP protocol. The mibs that are used to find the connectivity between network devices are given below,
i) BRIDGE-MIB
ii) RFC-1213-MIB
iii) CISCO-CDP-MIB.
Most other vendors switches support Bridge MIB. So for non-Cisco-devices, we can get the connectivity details from this mib. If you still encounter the error, it is due to OpManager using RFC1213 and ipRouteTable to create the maps. This RFC has been deprecated and has been replaced by RFC2096 and ipCidrRouteTable. This can be replicated with Mib Browser. Try to see if your device is compliant with RFC1213 or RFC2096. There should soon be a patch from the team to ensure that all devices are mapped correctly.
Configuring SNMPv3 on a router
Here are the steps to configure SNMPv3 on arouter. Lets configure a privileged User called Henry with the relevant details below.
- username : Henry
- authProtocol : MD5
- privProtocol : DES
- authPassword : authUser
- privPassword : privUser
- contextname : priv
Configure the user in router using the following commands,
1. First telent the router .
2. Check whether the engineID is already configured or not using the below commands
show snmp engineID
If it shows engineID details so there is no need to issue the belowcommands. If the above command gives empty result, issue the belowcommand.
snmp-server engineID local 8000063000100a1ac151003
3. Create the view for read / write / notify.
snmp-server view readview internet included
snmp-server view writeview internet included
snmp-server view notifyview internet included
4. Create the user
snmp-server user Henry privGroup v3 auth md5 authUser priv des56 privUser
5. Map the user with group.
snmp-server group privGroup v3 priv read readview write writeview notify notifyview
Thats all.. Snmp V3 is correctly configured in that Router.
Now to check whether its done properly do a snmpwalk using the following command
snmpwalk -d -v 3 -a MD5 -A authUser -l authPriv -u Henry -x DES -X privUser <TargestHostName>:<TargetPort> system
Ex: snmpwalk -d -v 3 -a MD5 -A authUser -l authPriv -u Henry -x DES -X privUser proto-test3:161 system
If you can see some reply in the command line it really works Smile
For Detailed information on SNMP v3 configuration on Routers please check the below link
http://www.cisco.com/en/US/docs/ios/12_0t/12_0t3/feature/guide/Snmp3.html
Now add a new Credential in OpManager under Admin --> CredentialSettings with those relevant details and add a new device to OpManagerand then check whether it helps. Do let me know how it works.
Interfaces are not shown in the routers map.
Some users experience the issue of 'missing interfaces' when viewed in the Infrastructure view. Understanding how discovery of interfaces happens in OpManager will make the reasons easier to understand.
OpManager queries the ifTable and ipAddrTable of RFC1213-MIB with configured SNMP parameters for that device in OpManager. For the ifIndexes(OID: .1.3.6.1.2.1.2.2.1.1) present in ifTable , if there is an ipAdEntAddr(OID: .1.3.6.1.2.1.4.20.1.1) in ipAddrTable then that will be added as an interface in SnmpInterface table along with its properties like speed, index, description, phyMedia, phyAddress and parent-device. If the address is pingable then the interface will be a managed one otherwise added as unmanaged interface. If the ifType is loopback or the ipAdEntAddr is 127.0.0.1 that interface will not be added. In OpManager the number of indexes present in ifTable are taken . If the interfaces don't have an IpAddress, then OpManager adds them in the format IF-<primary ip address of Router>-index along with its properties.If the device has more than two interfaces and ipForwarding(OID: .1.3.6.1.2.1.4.1) is enabled then that will be categorized as Router.
However,for devices other than Router, the unnumbered interfaces,the interfaces that have an ifIndexe but does not have an ipAddrEntAddr in ipAddrTable, will not be added.
If the Router is misconfigured, like two addresses hold same index in ipAddrTable then last one will be added while first one will not be added and so will be missing from the Router view.This limitation is because for us index is a key so no duplication is entertained in that.
To resolve this issue, check if is there anything wrong with the routers IOS if duplication of indexes is there and fix those issues. Following this, delete and re-add the device.
Color-coding to show interface status
| Admin |
Operational |
Status |
Colour coding |
| Down |
Up/Down |
Critical |
Red |
| Up |
Up |
Clear |
Green |
| Up |
Down |
Trouble |
Orange |
| Up |
Dormant(Ready to receive/ transmit packets) |
Clear |
Green |
| Up |
Not Present /Unknown/testing |
Attention |
Yellow |
If the Admin and Operational status are UP, and also the threshold is violated for any of the monitor in the interface, the port will be moved to the trouble state (Orange color).
Monitoring Cisco Routers temperature
If the SNMP Agent responds to the Temparture OID from the Cisco-ENVMON MIB, then you can monitor the Cisco Router Temperature in OpManager
Monitoring a specific route or next-hop address of a router
First,we need to make sure that the route to be monitored is in the Routing table of the router.To check this,please run the show IP route in the privileged mode.
For example :
cisco2811#show ip route
Gateway of last resort is 192.168.118.2 to network 0.0.0.0
C 192.168.118.0/24 is directly connected, FastEthernet0/0
S* 0.0.0.0/0 [1/0] via 192.168.118.2
As seen above,the route for network address 192.168.118.0 exists in the routing table (in this case it is directly connected)
If the next-hop address for the network address 192.168.118.0 is known we can monitor this route.
In Default RFC-1213MIB,we have the OID IPRouteNextHop (.1.3.6.1.2.1.4.21.1.7) this will provide the entire routing table information.
ipRouteNextHop.0.0.0.0:-->192.168.118.2
ipRouteNextHop.192.168.118.0:-->192.168.118.23
As seen in the above output,the next-hop address is 192.168.118.23 which is the expected behavior.
In order to monitor this specific route of 192.168.118.0,we can append the network address with the above mentioned OID i.e. 1.3.6.1.2.1.4.21.1.7. 192.168.118.0
So,for this OID (.1.3.6.1.2.1.4.21.1.7. 192.168.118.0) the Output in MIB will be the IP of the next hop.
Once you find the OID of the Specified Route, you can easily monitor the Route by adding custom SNMP monitor.
Add the IP address as a string OID by unchecking the Numeric box.
If the next hop does not contain this IP address(192.168.118.0) it can be set as the threshold value and you will get the alarm. If it contains this IP address (192.168.118.0) it can be set as the rearm value where there is no alarm or alarm is cleared.
Now associate the monitor to the device.
Difference between SNMP Traps and SNMP Monitors
| S.No |
SNMP Monitors |
Traps |
| 1 |
Pull Model: OpManager sends SNMP request to the SNMP agent running on the monitored device and receives the response. |
Push Model: Monitored device(SNMP agent) sends messages in the form of traps to the trap destination(OpManager) |
| 2 |
Communication: both ways(UDP 161) |
One way. Only from device to trap destination (UDP 162) |
| 3 |
SNMP requests can be scheduled using monitoring intervals. |
Traps are spontaneous. They will reach the destination as soon as they are generated. |
| 4 |
Custom SNMP monitors can be created for the non default metrics. These monitors convert the raw SNMP response into a meaningful metric with unit. |
Custom SNMP Trap processors are can be created for the new trap messages. They process the trap messages and convert them into meaningful alarms.
If there is no trap processor, traps will be dumped under Alarms-->Unsolicited traps. |
| 5 |
SNMP community string is mandatory to get a SNMP response |
Community string is not mandatory to receive the trap message. |
Problem in Switch Port Mapper
Switch Port Mapper does not display the MAC Address and the IP Address fully.
The Router input may not be specified or the ARP cache may not be updated.
1. The Router input is not specified. Enter the Router name to map the MAC Addresses to IP Addresses. The Router should be in the same subnet as that of the devices connected to the switch.
2. If the router input is not given, the information is obtained from the ARP cache of the switch. A cache file is also maintained locally to store this information. Perform a ping scan of the subnet to update the cache and then perform Switch Port mapping. This will improve the MAC to IP resolution.
If the above things are correct, please do the steps below
1. Open the MIB Browser from <OpManager>\\Bin Folder
2. Host Name ( Switch Name )
3. provide the community String of this device
4. Click on Load MIB and load the BRIDGE.MIB
5.Now try to query these values BRIDGE.MIB -->> mib2-->>.iso -->> org -->> dod -->> internet-->> mgmt-->> mib-2 -->> dot1dBridge -->>dot1dTp -->>dot1dTpFdbTable -->> dot1dTpFdbEntry -->>dot1dTpFdbAddress
Try to query these values. If you get repliesalong with the MAC Address thenthe values will be displayed in the SWITCH PORT MAPPER.
What is an SNMP Trap?
Traps are cryptic messages of a fault that occurs in an SNMP device. SNMP traps are alerts generated by agents on a managed device. These traps generate 5 types of data:
- Coldstart or Warmstart: The agent reinitialized its configuration tables.
- Linkup or Linkdown: A network interface card (NIC) on the agent either fails or reinitializes.
- Authentication fails: This happens when an SNMP agent gets a request from an unrecognized community name.
- egpNeighborloss: Agent cannot communicate with its EGP (Exterior Gateway Protocol) peer.
- Enterprise specific: Vendor specific error conditions and error codes.
What are 'Authentication Failure' alarms?
Authentication failure alarms are raised due to some monitoring system trying to access the device with wrong community strings. It may be opmanager or some other monitoring system installed in your network sending snmp queries with wrong community strings.
Configure the correct community strings. In Opmanager it is under Configure--> Passwords. Also check other installations of opmanager or third party monitoring applications for wrong community strings.
If you need to know a clear picture on this issue, like which device sends the wrong SNMP community string. Install a packet sniffer software(www.ethereal.com) on the device which sends the authentication traps and capture packets. By analyzing the capture packets, you can find the device which sends the SNMP query with wrong community string. Send us the captured packets for analysis along with IP address of OpManager server and from device which youre getting authentication traps.
What is meant by Rearm Value' in the threshold settings?
Rearm value is the value which the determines the monitor has restored to normal condition. For instance, the threshold condition for a memory monitor is selected as greater than [>] and the threshold value is configured as 75. The monitored memory value of that device is 80. Now alert is raised and the monitor is in violated condition. At the next poll the monitored value is 72. An alert for returning to normal condition is generated. At the next poll again the monitored value goes to 80. Again a threshold violation alert is generated. In order to avoid this, enter the rearm value. Only if the monitored value reaches the rearm value the monitor goes to the normal condition and a normal alert is raised. Note: If you select threshold condition greater, then the rearm value should be lesser than the threshold value and vice versa.
Traps are not received in OpManager
Check below for the possible reasons for not receiving the traps and its corresponding resolution.
1. Trap port might be occupied in opmanager server. ---> Make sure the that trap port of OpManager is not occupied by trap service of Operating System (ie) port 162 should be free. If not free it and restart opmanager.
2. Device might not be monitored in OpManager. --> Device should be added in OpManager to receive the traps from that device.
3. Trap destination might be wrong --> OpManager server should be the trap destination for the device which sends traps.
If the issue persists, follow the steps below to check whether the trap is received properly on the OpManager server.
1. Stop OpManager. Make sure the port 162 is not occupied.
2. Open the file MibBrowser.bat located under \OpManager\bin folder.
3. Go to View --> Trap Viewer and check whether the traps are received properly.
4. If the traps are not received in the trap receiver, the traps are not reaching the OpManager server and you can sort that problem which will make OpManager receive the traps.
5. If you are receiving the traps on the trap processors and not on OpManager, contact Support.
Receiving traps on different ports
Edit the file "trapport.conf" under /OpManager-Home/conf. Change the port from 162 to the one you wish. Restart OpManager for the changes to take effective.
Will the layer2 maps work only for Cisco switches?
No, Layer-2 maps work for non-Cisco devices as well. You might sometimes encounter the error,"No switch links found for this device. Please select different seed device" when trying to draw network maps for non-Cisco devices. To get the Layer-2 maps for other vendor switches, it must meet the following criteria:
- the switches must support SNMP protocol
- must have the BRIDGE-MIB implemented (most vendoes support this MIB)
If you still encounter the error, it is due to OpManager using RFC1213 and ipRouteTable to create the maps. This RFC has been deprecated and has been replaced by RFC2096 and ipCidrRouteTable. This can be replicated with Mib Browser. Try to see if your device is compliant with RFC1213 or RFC2096. There should soon be a patch from the team to ensure that all devices are mapped correctly.
What is the algorithm Used in OpManager to find the Network Connectivity?
There are many mechanisms available to find the network connectivity. OpManager uses the general algorithm to find out the connectivity between switches, routers and network devices using SNMP. Layer 2 network connectivity falls under the category as mentioned below.
i) Router to Router connectivity.
ii) Switch to Switch connectivity.
iii) Switch to Network devices such as Router, Firewall, Access Point connectivity.
iv) Router to subnet connectivity.
v) End devices connected to a switch.
Router to Router connectivity / Router to subnet connectivity :
The routing algorithm is configured on all the routers and routing table details can be fetched from the router by querying ipRouteTable of RFC1213-MIB. The ipRoutable table contains an entry for each route present in the router.
The oids that we query are,

This routing table contains both direct and indirect routing path from a particular device. This implies that the router interface is directly connected to another router interface without intermediate switch or hub.
ipRouteDest - The destination IpAddress of this routing path may be network address or a router ip address.
ipRouteIndex - The interface through which the next hop of this routing path should be reached.
ipRouteNextHop - The ipaddress of the next hop of this routing path. It contains either source ipaddress i.e same ip address in case it is connected to a network or connected router ip address.
ipRouteType - The type of this routing path ( direct, indirect, invalid etc).
If routing type is direct it implies that we can reach the subnet which is specified in the ipRouteDest through this interface and the next hop contains the same ip address of this router. The interface can be identified by the route index value. So we will obtain the router to subnet connectivity as switch link object. The switch link object is formed in such a way that source --> destination along with connected interface.
If routing type is indirect, it means that the router is connected to another router. We have the source router and remote router ip address, which is obtained in the next hop node, and the interface index. So we will determine the router to router connectivity.
For example, Router 192.168.112.7's iproutingTable output,

The router 192.168.112.7 is connected to 192.168.116.12 via 192.168.112.7's interface 2. Also the subnet 192.168.112.0 is reached via this router.
Switch to Switch Connectivity
The management information base (MIB) objects required to find the switch connectivity is as follows:

OpManager implements the Topology discovery algorithm which is explained in "Ip Network Topology Discovery using SNMP" ( Click the link). To find the switch to switch connectivity OpManager uses the values in the above table. The Bridge mib dot1dTpFdbTable contains MACAddress of the device which is reachable via this switch as well as port and status info. The dot1dTpFdbStatus can be in one of the five states- other ( 1 ) , invalid ( 2 ) , learned ( 3 ) , self ( 4 ) , mgmt ( 5 ). The type learned refers to active device connection. OpManager considers this type alone to find out the connectivity. This table has macaddress with port relationship and its corresponding ifIndex is obtained by querying the dot1BasePortTable. This gives only mac address of the device, so ipaddress of the device is obtained by querying RFC1213-MIB's ipNetToMediaTable.
The main algorithm is
1. Switch set = Filter the L2, L3, L4, and L7 switches that support Bridge MIB
2. Switch pair set = Make pairs of switches; if there are n switches there will be n2 sets
3. For each switch pair set, for ex: { Si, Sj}
a) Get the set of MAC for Si i.e., {Mia..Mil} from ifPhyaddress
b) Get the set of MAC for Sj i.e., {Mja..Mjk} from ifPhyaddress
c) If AFT of one of the dot1dBasePortEntry (Pi and Pj) of Si and Sj has at least one MAC address Mil and Mjk of each other
then
i) Get the mapping of Pi and Pj with the ifIndex Ifi and Ifj
ii) Set the connectivity of Si and Sj for interface Ifi and Ifj
iii) Store the connectivity information in database.
Switch to network device connectivity using CDP
Cisco Discovery Protocol (CDP) is propitiatory data link layer protocol which is developed by Cisco system. It is used to share information about directly connected Cisco devices. The above details are obtained by querying the tables below:

- cdpCacheIfIndex - The interface by which the device is reached i.e ifIndex of the cisco device.
- cdpCacheAddress - IpAddress of the device which is connected to this cisco device.
- cdpCacheDevicePort - The connected device's interface or port description.
When the above table is queried, OpManager forms the switch link between the cisco device and the connected devices. This is because this table has the ip address of the connected devices as well as the details of interface through which it is connected.
How does Antivirus impact OpManager?
At times, Antivirus running on OpManager server can lead to database corruption (though there are other reasons that trigger database corruption like running of 3rd party utilities like Symantec for backup etc). To overcome this trouble, try stopping the Anti virus or backup utility temporarily and verify the status. You can also try to exclude OpManager from Antivirus to prevent this if that causes the problem.
Running Antivirus like Mcafee, Trend Micro etc can also block discovery or prevent OpManager startup. You need to remove the port block from the Access Protection configuration in the Antivirus or unblock java.exe if OpManager doesn't start. In the case of few Antivirus apps, excluding the files/folders from the scan will work.
Which IP SLA should be enabled – udp jitter or RTP or both. What is the difference?
You need to enable UDP jitter.
UDP Jitter Operation Vs RTP VoIP Operation
UDP Jitter is an operation that sends a stream of UDP test packets specially crafted for performance measurement. There is another operation called "RTP VoIP". There are fundamental differences between the two:
RTP VoIP sends a real RTP stream, while UDP Jitter sends a simulated stream. Both looks the same from the outside, but RTP VoIP packets contains a real RTP stream.
RTP VoIP uses and requires at lease one hardware codec to run. It needs DSP resources and voice interfaces to run on.
RTP VoIP will compute the MOS score based on the delay and number of DSP frames lost. UDP Jitter provides IP-based metrics, while RTP VoIP provides DSP-based metrics.
RTP VoIP is an operation that is very specific for VoIP, and UDP Jitter is more generic.
RTP VoIP is not designed to be deployed at large scale, while UDP Jitter is.
It is recommended to use UDP Jitter as much as possible, and it will be enough for the large majority of the cases. When more detailed information is needed, or for troubleshooting purposes, an RTP VoIP operation can be triggered on demand at specific time and location. RTP VoIP is not meant to replace UDP Jitter.
Courtesy: Info sourced from here:
http://docwiki.cisco.com/wiki/IOS_IP_SLAs_UDP_Jitter_Operation_Technical_Analysis
Does OpManager monitor real-time SIP and RTP traffic?
OpManager uses IP SLA's UDP jitter operation to determine the connection jitter, round-trip-time, packet loss and latency. It therefore uses this synthetic traffic to simulate traffic close to the real time traffic and does not monitor it real time. The function of IPSLA is to identify quality issues proactively by simulating the real time environment.
The need to use synthetic traffic can best be illustrated with an example. Let us assume that a call is scheduled for your CEO with a prospective client at 3.00 PM on a particular day. For some reason, the VoIP connectivity breaks at around 2.30 PM and the concerned people are not aware. Imagine you or the CEO discovering the issue just when the call commences! This is a situation a VoIP administrator would dread to be in. This is where, the method of sending synthetic traffic over the same WAN link through which traffic flows real time, helps.. You would have identified the packet drop much earlier and could have worked around the bottleneck much earlier.
What are the prerequisites for configuring VoIP monitors in OpManager?
OpManager primarily relies on Cisco's IP-SLA for monitoring the VoIP QoS metrics between two locations, therefore both the locations should have Cisco Router enabled with IPSLA agent. From IOS Version 12.3(14)T all Cisco routers support monitoring of VoIP QoS metrics
When you want to test a link from your office to another location, you need a Cisco router enabled with IPSLA agent ( IOS version 12.4 or later ) at each end.
Can NFA and OpManager be installed on the same system?
Yes, both can be installed on the same system provided there are no port conflicts. You can change the OpManager ports as follows:
1. Open the file Ports.properties under \OpManager\conf folder.
2. Change the TOMCAT_SHUTDOWNPORT to 8015.
3. Save it and start OpManager.
The error message is "Internal Server error" or "OpManager Service --- open failed", is encountered when NFA and OpManager are installed on the same machine.
This issue could possibly happen if the ports needed by OpManager are already occupied. So try following the steps below and change the Tomcat shutdown port and then check if it helps.
1. Open the file Ports.properties under \OpManager\conf folder.
2. Change the TOMCAT_SHUTDOWNPORT to 8015.
3. Save it and start OpManager.
Can OpManager monitor LUN on VMware?
Yes, OpManager has extensive disk monitors, with graphical reports for the following:
- Disk I/O usage
- Disk Read Speed
- Disk Write Speed
- Disk Read Requests
- Disk Write Requests
- Disk Bus Resets
- Disk Command Aborts
- Disk Read Latency
- Disk Write Latency
- Disk Space Usage
OpManager pulls the details via the API, so make sure you configure the VMware credentials properly. You can access the monitor details from the host snapshot page and can see the reports on per VM basis too. Here's a screenshot for reference:

What are 'unknown' devices?
To start with, it is important to understand how OpManager categorizes the devices into servers, routers, switches etc. OpManager relies on industry standard protocols like SNMP, CLI, and WMI to 'identify' the devices. SNMP is the standard protocol across all device categories while CLI is specific to Unix-based servers, and WMI is specific to Windows environment.
A device is grouped under 'Unknown' devices view due to the following reasons:
- Does not have one of these protocols enabled.
- In-correct user name and password or a user does not have the required privilege. For instance, WMI expects the user to have domain administrator's privilege.
- An Anti-virus or a Firewall does not allow OpManager to access.
- Network configuration that restricts access to some information on the systems in your network.
- Few security settings in case of Windows environment that dis-allows access.
Devices classified under 'Unknown' category
So, even if OpManager is able to ping and discover the device successfully, it does not know where to put the device and therefore classifies it under 'Unknown'! If you find any of your servers or other infrastructure device missing in the relevant category map, select the Maps --> Unknown category view and check if it is present here. You can move such devices to the relevant category, or rediscover them after enabling the SNMP/ CLI/WMI protocol and configuring the credentials.
What are the different Availability states and their meaning in OpManager?
Here are the Availability STATE information:
1. ACTIVE = 1 corresponds to the Device in UP state.
2. DOWN = 2 corresponds to the Device in DOWN state.
3. DEPENDENT_UNAVAILABLE = 3 corresponds to the DEPENDENCY DEVICE's down state.
4. ON_HOLD = 4 corresponds to the state when the Device is UNMANAGED ( like via Actions -> UnManage )
5. ON_MAINTENANCE = 5 corresponds to the device state when it is part of a DOWNTIME SCHEDULE that is in progress
6. PARENT_DOWN = 6 corresponds to the interface state when the parent ( device on which the INTERFACE is present) is down
7. PARENT_UNMANAGED = 7 corresponds to the interface state when the parent ( device to which the INTERFACE is present ) is UNMANAGED
In the database,this STATE column is present in the ManagedObject Database table
What is VoIP Codec?
Codecs (Coder/Decoder) serve to encode voice/video data for transmission across IP networks. The compression capability of a codec facilitates saving network bandwidth and it is therefore appropriate that you choose the correct codec for your IP network. Here is a quick reference to the codecs with the corresponding packets size and bandwidth usage:
| Codec & Bit Rate (Kbps) |
Operation Frequency |
Default number of packets |
Voice Payload Size |
Bandwidth
MP or FRF.12
(Kbps) |
Bandwidth
w/cRTP MP or FRF.12
(Kbps) |
Bandwidth
Ethernet
(Kbps) |
G.711a/u
(64 kbps) |
60 msecs by default. You can specify in the range of 0 - 604800 msecs. |
1000 |
160 + 12 RTP bytes |
82.8 kbps |
67.6 |
87.2 |
G.729
(8 kbps) |
1000 |
20 + 12 RTP bytes |
26.8 kbps |
11.6 |
31.2 |
Why is the source router field empty when configuring the VoIP monitor?
In order to monitor VoIP between two locations, you need to specify the links that you want to monitor using OpManager, that is, specify the source and target. The source router (Cisco router with IP SLA agent enabled) must be discovered in OpManager first. Only if this router is discovered in OpManager with valid SNMO read and write community strings configured, you will see the router listed as a source device and you will be able to pick so that you can successfully add a VoIP monitor.
Please follow these steps to discover a source router in OpManager
1. Go to the source router telnet session and enable snmp read and write communities.
2. Go to Admin -- Credential Settings -- New
Enter valid read and write communities which is enabled in the source device.
3. Go To Admin --Add Device
Enter the name or IP address of the source device, select the newly added credential and then click on Add Device.
4. Go to VoIP Monitors -- Settings
Select newly added source router and proceed with the configuration.
Why is incorrect disk space reported for the datastore on an VMware ESX?
Connect to that ESX host via vSphere client and do a refresh datastore.You can infact automate this refresh to happen every 5/10 minutes by creating a cronjob. Here is the procedure as cited by one of OpManager users in our forums- a nice workaround:
1. Connect to your ESXi with SSH or Telnet
2. Open your root file in your crontabs directory with the vi editor:
vi var/spool/cron/crontabs/root
3. Edit the file and put the following line in it:
*/5 * * * * /bin/vim-cmd /hostsvc/datastore/refresh <your_datastore_name>
4. Save the file
5. Restart the cron daemon
6. Be happy
Now the datastore you configured at <your_datastore_name> will be refreshed every 5 minutes.
Why is 'Disabling interface failed' error message encountered when trying to disable an interface on a Cisco ASA 5500 firewall?
This message is encountered when trying to turn interfaces on and off using the Interface Enable/Disable button (drill down to the interface level). To perform this action, OpManager requires the write community to be enabled for the device in OpManager. Whenever you enable or disable any interface of the device in OpManager, it will write them on the router or switch using the write community.
So, check if you have configured the correct write community on the device in OpManager and give a try again.
Unable to delete a WAN RTT Monitor.
When trying to delete a WAN RTT monitor, the following error is encountered:
[Exception in:/webclient/common/jsp/PageNavigation.jsp] null
A possible corruption of the Cisco RTT MON MIB could cause this error when trying to delete a WAN RTT monitor.
Copy this MIB to the \OpManager\mibs folder replacing the original file and restart OpManager service. You must be able to delete the monitor now.
When moving the database to another SQL server, what kind of permission does it require?
OpManager accepts only SQL Authentication credentials with DB Owner & DB Creator rights.
What are the specific default ports that should be open for a server to be monitored by OPManager?
By default OpManager uses the following ports to monitor devices ..
SNMP-161
SNMP Traps - 162.
WMI - 135 & 445
Telnet - 23
SSH - 22
ICMP ping
How is traffic utilization calculated in OpManager?
32-bit counters:
Ref mib: RFC-1213-MIB
Ref tables: ifraw(raw data), ifhourlysum(Sum up collected raw data for every hour and stored in this), ifhourlyrate, ifdailysum,ifdailyrate
In Traffic(bps) : InOctets*8*1000/deltatime ()
Out Traffic(bps): OutOctets*8*1000/deltatime
In Packets per sec: (INUCAST+INDISCARDS+INERRORS+INUNKNOWNPROTOS+INNUCAST)*1000/deltatime
Out Packets per sec: (OUTUCAST+OUTNUCAST)*1000/(DELTATIME)
In Bytes: INOCTETS
Out Bytes: OUTOCTETS
In Util(%) : (InTraffic/Inspeed)*100 = (InOctets*8*1000*100/deltatime*inspeed)
Out Util(%):(OutTraffic/OutSpeed)*100 = (OutOctets*8*1000*100/deltatime*Outspeed)
Total util(%): (Inutil+outUtil)/2
64-bit Counters:
Ref mib: RFC-1213-MIB,IFMIB
Ref tables: ifhcraw(raw data), ifhchourlysum(Sum up collected raw data for every hour and stored in this), ifhchourlyrate, ifhcdailysum,ifhcdailyrate
In Traffic(bps) : InOctets*8*1000/deltatime
Note: we will poll for .1.3.6.1.2.1.31.1.1.1.6.ifIndex to get In Traffic. Sometimes agent may implement 64-bit counters partially for interfaces. In that case query to .1.3.6.1.2.1.31.1.1.1.6.ifIndex oid will give zero values. At the time we will take 32-bit counter value. We will query to .1.3.6.1.2.1.2.2.1.10.ifIndex
Out Traffic(bps): OutOctets*8*1000/deltatime
Note: we will poll for .1.3.6.1.2.1.31.1.1.1.10.ifIndex to get In Traffic. Sometimes agent may implement 64-bit counters partially for interfaces. In that case query to .1.3.6.1.2.1.31.1.1.1.10.ifIndex oid will give zero values. At the time we will take 32-bit counter value. We will query to .1.3.6.1.2.1.2.2.1.16.ifIndex
In Packets per sec: (INUCAST+INDISCARDS+INERRORS+INUNKNOWNPROTOS+HCINMCAST+HCINBCAST)*1000/deltatime
Out Packets per sec: (OUTUCAST+HCOUTMCAST+HCOUTBCAST)*1000/(DELTATIME)
In Bytes: INOCTETS
Out Bytes: OUTOCTETS
In Util(%) :(InTraffic/Inspeed)*100 = (InOctets*8*1000*100/deltatime*inspeed)
Out Util(%):(OutTraffic/OutSpeed)*100 = (OutOctets*8*1000*100/deltatime*Outspeed)
Total util(%): (Inutil+outUtil)/2
When logging into OpManager with correct credentials, the login page continues to prompt the user with "Please enter the user name". Why?
You may experience this if there is some issues in the database. Please try restarting OpManager and check if it works. Else, email the Support information file for analysis.
Error message "Please enter a valid number" is encountered when configuring discovery. Why?
Opmanager might throw this error when there is a dot(.) in the IP Address. If this is not the case, email the exact IP and the netmask to our support to help reproduce and resolve the error.
When the WMI disk queue length monitor is enabled in OpManager, what disk is it providing data for? Is it possible to specify which disk it is monitoring?
The inbuilt monitor for WMI based Disk Queue length is for all disks(ie "_Total"). If you want this for a specific disk, use custom WMI monitor.
Performance Monitors--Add Monitors--->WMI monitors
This will list all the available classes. When you select disk queue length, you can see the partitions as instances. Select the partition and add monitor. Note that the disk queue length monitor is found under the WMI-based Disk Monitors.
When configuring script monitors, what is the ideal 'Timeout' to be configured?
It depends on the job done by the scripts. Use the Test script option to determine the approximate timeout period. If the scripts perform very basic operations, 10 seconds would suffice.
What is the minimum monitoring interval configurable for script monitors?
Every time, the script content is written to a file in disk and this takes some time. Monitoring interval also depends on the number of script monitors associated. (though we haven't determined the exact number yet!). We suggest that you configure a 10 min monitoring interval for local scripts and 15 mins for scripts running on remote machines.
A custom query joining snmpinterface table and alert tables to report on IFCIRCUITID and IFALIAS for Discard or Error alerts. (this was a user request on our forums)
A sample query:
(SELECT al.*,si.ifalias,si.ifcircuitid FROM IntferrorThreshold idt INNER JOIN ManagedObject mo ON idt.id=mo.moid INNER JOIN SNMPInterface si ON mo.name=si.name INNER JOIN Alert al ON al.entity=CONCAT("IF_ERROR_",idt.id))
UNION
(SELECT al.*,si.ifalias,si.ifcircuitid FROM IntfdiscThreshold idt INNER JOIN ManagedObject mo ON idt.id=mo.moid INNER JOIN SNMPInterface si ON mo.name=si.name INNER JOIN Alert al ON al.entity=CONCAT("IF_DISCARD_",idt.id))
Error: Device already present in the system and Some stray entries found for this device.
These errors occur because of stray entries for these devices in the database from their previous discovery. This is resolved by cleaning up the entries from the relevant tables. Here is how you do it:
- Extract the enclosed Zip file to the OpManager installation directory. This will create a new folder "RemoveDBEntires" and 4 files will be kept under that folder.
- Run the script RemoveDBEntries.bat(RemoveDBEntries.sh for Linux) both using IP Address and Device name. Make sure the server is running, when you execute the script. Thisscript will remove the partially added entries from the database.
- RemoveDBEntries script accepts the device name and ip address as argument.
cmd> cd [OpManager Home]/RemoveDBEntries
cmd> RemoveDBEntries.bat IPaddress
cmd> RemoveDBEntries.bat <devicename>
Example:
\\OpManager\\RemoveDBEntries>RemoveDBEntries.bat 192.168.12.34
\\OpManager\\RemoveDBEntries>RemoveDBEntries.bat opman.zohocorp.com
This script will remove the partially added entries from the database.
- After executing the script, please restart OpManager service and add the device.
Note: It may take couple of minutes to view the newly added device.
OS: Windows 2000 and above / R.H. Linux 7.2 and above.
Attachment : RemoveDBEntries.zip for Version 7 and above
2006_11_8_12_34_26_RemoveDBEntries.zip for Version 6
RemoveDBEntriesNew.zip for OpManager 8030 & above (till build 8052)
RemoveDBEntriesNew-8720.zip for OpManager build 8700 & above
Note 1: Use RemoveDBEntriesNew.zip only for OpManager build 8030 and above (till build 8052 ) , here the zip file will create a folder in the name of RemoveDBEntriesNew instead of RemoveDBEntries while extracting. Follow the same steps above from the cmd> cd [OpManager Home]/RemoveDBEntriesNew directory instead of cmd> cd [OpManager Home]/RemoveDBEntries.
Note 2: Use RemoveDBEntriesNew-8720.zip only for OpManager build 8700 & above , here the zip file will create a folder in the name of RemoveDBEntriesNew instead of RemoveDBEntries while extracting. Follow the same steps above from the cmd> cd [OpManager Home]/RemoveDBEntriesNew directory instead of cmd> cd [OpManager Home]/RemoveDBEntries.
Attached Files :
2006_11_8_12_34_26_RemoveDBEntries.zip
RemoveDBEntriesNew_9010.zip
RemoveDBEntries.zip
RemoveDBEntriesNew-8720.zip
RemoveDBEntriesNew.zip
Unable to load the Cisco ENVMON MIB. Why?
This can happen if a dependent mib is missing. Please download the attachment, place it under OpManager\mibs folder and try again.
CISCO-SMI.mib
What is the difference/relationship between the monitoring interval configured for the device category vs that of the monitored interval for a specific monitor?
Admin->Monitoring Intervals => Device availability monitoring using ping. Is done at the interval configured here.
Monitor specific interval => Data collection interval for that metric alone(WMI/SNMP/CLI). Irrespective of the device availability monitoring interval, the particular performance parameter is monitored at the interval specified here, at the monitor level.
Both are necessary for overall device health monitoring.
Applying device template to a device manually classified into a category, the monitors from the template are not associated to the device. Why?
Let us assume you have manually classified a device into Windows2008 category and then go on to apply the Win2008 template to the device to associate monitors.. The template is not applied properly for the following reasons:
1. If you are running OpManager on Linux and the template has WMI-based monitors.
2. If you have installed on Windows, but have not configured the WMI authentication credentials for the monitored device (in this case, the win 2008 device)
3. If the device has SNMP and you have not provided the SNMP credentials for the device.
Configure the credentials for the device and proceed with applying the template.
Why does opmanager have to run as root under linux?
OpManager has an in-built MySQL and TOMCAT which needs lot of changes to run as non-root user. So we didn't provide this option. It is the same for all our ManageEngine products.
What do the different severity levels in OpManager mean?
OpManager has four different severity levels for the alarms. Severity levels of device down alarms (availability monitoring) are already predefined
Here is the list with the severity and the events which will trigger the alarms with these severities
1)Service Down: When is service down and URL monitor is down
2)Attention: When the device is down for the 1st poll in availability
3)Trouble: When the device is down for 3 consecutive polls in Availability
4)Critical: When the device is down for 5 consecutive polls in Availability. This is the highest severity in OpManager.
5)Clear: At any stage if an alarm is cleared.
As you can see, the severity will automatically change for the device down alarms based on the number of missed polls.
Similar to device down alarms, Interface down alarm severity(Trouble) is also predefined.
But for other alarms like threshold violation, Traps and event logs, user can configure any severity(Attention or Trouble or Critical) and the severity will be the same even if the alarm is repeated.
The database tables in OpManager storing performance data for reporting.
The details of the tables are:
The performance data tables in OpManager 7 are quite distributed, enabling better reporting. Here is a quick summary of the tables that you will need to take custom reports
1. ElementsAvailabilityHourly - Every day device availability reports are taken from this table.
2. ElementsAvailabilityDaily - This table is queTried for availability reports for over a week. Has data archived every 24 hours.
3. IfRaw_<date> - This table has data of interface traffic, errors, discards etc
4. IfHourly_<date> - This has values archived every one hour for all the interface data
5. IfDaily_<date> - This has values archived every 24 hours
OpManager archives the above performance tables after the row-count exceeds apprx 250,000 rows. So, to know the date of the table to be queried, query the table METATABLE. This lists all the perforformance tables. The current performance tables (the names of which are mentioned above) will have the value as -1 for ENDTIME field.
Each element/device is a managed object and has a unique ID, which you can retrieve using MOID field in the ManagedObject table. The value of this MOID is the same as ElementID field in the above tables. So, you can use a join between these two tables to create custom reports.
Besides the above tables, the host resources data such as that of CPU, Memory etc are persisted in the following table:
1. Statsdata<current date>: This stores the current or raw data. That is, the data as and when collected. This table is created every 24 hours. New table is created at 12.00 midnight.
2. Statsdata_hourly: Which has values archived every one hour. Hourly data is stored for a period of 15 days by default and can be set to a maximum of 90 days.
3. Statsdata_daily: Which as values archived every 24 hours. Daily data is stored for a default period of 1 year and can be set to store for a max of 10 years.
For additional information refer to DatabaseSchema.conf located under OpManager/conf folder
I still have some questions which needs clarification!
If you have any questions about OpManager, feel free to raise a support request and we’ll get back to you.